13. 🛠️ Exercise - Exploratory Data Analysis (EDA) | Example 01#
![]()
helps you understand dataset
detect potential issues
and refine preprocessing steps
13.1. Workshop Sample Dataset#
# 📌 Step 1: Install Required Libraries (If Not Installed)
!pip install opencv-python numpy pandas matplotlib tqdm albumentations
# 📌 Step 2: Import Necessary Libraries
import os
import requests
import zipfile
from tqdm import tqdm
import pandas as pd
import numpy as np
import cv2
import matplotlib.pyplot as plt
from glob import glob
from collections import Counter
# 📌 Step 3: Define Dataset URL and Paths
dataset_url = "https://storage.googleapis.com/nmfs_odp_pifsc/PIFSC/ESD/ARP/pifsc-ai-data-repository/fish-detection/workshop/fish_dataset.zip"
dataset_zip_path = "/content/fish_dataset.zip"
dataset_extract_path = "/content/fish_dataset/"
13.2. Download Dataset#
# 📌 Step 4: Download the Dataset from Google Cloud Storage
def download_file(url, output_path):
response = requests.get(url, stream=True)
total_size = int(response.headers.get("content-length", 0))
with open(output_path, "wb") as file, tqdm(
desc="Downloading Dataset",
total=total_size,
unit="B",
unit_scale=True,
unit_divisor=1024,
) as bar:
for data in response.iter_content(chunk_size=1024):
file.write(data)
bar.update(len(data))
# Download only if it doesn't exist
if not os.path.exists(dataset_zip_path):
download_file(dataset_url, dataset_zip_path)
else:
print("✔ Dataset already downloaded.")
Downloading Dataset: 100%|██████████| 39.5M/39.5M [00:04<00:00, 9.34MB/s]
13.3. Extract Dataset#
# 📌 Step 5: Extract the Dataset
def extract_zip(zip_path, extract_to):
with zipfile.ZipFile(zip_path, "r") as zip_ref:
zip_ref.extractall(extract_to)
print(f"✔ Extracted dataset to {extract_to}")
# Extract only if the folder does not exist
if not os.path.exists(dataset_extract_path):
extract_zip(dataset_zip_path, dataset_extract_path)
else:
print("✔ Dataset already extracted.")
✔ Extracted dataset to /content/fish_dataset/
13.4. A YOLO Object Detection Dataset should be in 1 of 2 folder structures#
fish_dataset/
├── train/
│ ├── images/
│ ├── labels/
├── val/
│ ├── images/
│ ├── labels/
OR
fish_dataset/
├── images/
│ ├── train/
│ ├── val/
│ ├── test/
├── labels/
│ ├── train/
│ ├── val/
│ ├── test/
# 📌 Print dataset.yaml content
yaml_path = "/content/fish_dataset/dataset.yaml"
if os.path.exists(yaml_path):
with open(yaml_path, "r") as file:
print(file.read())
else:
print("❌ dataset.yaml not found!")
train: images/train
val: images/val
# Number of classes
nc: 1
# Class names
names: ['fish']
# 📌 Step 6: Verify Dataset Structure
for split in ["train", "val", "test"]:
img_path = os.path.join(dataset_extract_path, "images", split)
lbl_path = os.path.join(dataset_extract_path, "labels", split)
# Ensure folders exist before counting files
img_count = len(os.listdir(img_path)) if os.path.exists(img_path) else 0
lbl_count = len(os.listdir(lbl_path)) if os.path.exists(lbl_path) else 0
print(f"✔ {split.upper()} - Images: {img_count}, Labels: {lbl_count}")
✔ TRAIN - Images: 786, Labels: 786
✔ VAL - Images: 196, Labels: 196
✔ TEST - Images: 0, Labels: 0
# 📌 Step 7: Run Exploratory Data Analysis (EDA)
dataset_root = dataset_extract_path # Set dataset path
# Define paths for train and validation sets
train_img_dir = os.path.join(dataset_root, "images", "train")
train_lbl_dir = os.path.join(dataset_root, "labels", "train")
val_img_dir = os.path.join(dataset_root, "images", "val")
val_lbl_dir = os.path.join(dataset_root, "labels", "val")
# Load train and validation image/label paths
train_image_paths = sorted(glob(os.path.join(train_img_dir, "*.jpg")))
train_label_paths = sorted(glob(os.path.join(train_lbl_dir, "*.txt")))
val_image_paths = sorted(glob(os.path.join(val_img_dir, "*.jpg")))
val_label_paths = sorted(glob(os.path.join(val_lbl_dir, "*.txt")))
# Print dataset statistics
print(f"📊 Total Training Images: {len(train_image_paths)}, Total Training Labels: {len(train_label_paths)}")
print(f"📊 Total Validation Images: {len(val_image_paths)}, Total Validation Labels: {len(val_label_paths)}")
📊 Total Training Images: 786, Total Training Labels: 786
📊 Total Validation Images: 196, Total Validation Labels: 196
# 📌 Step 9: Class Distribution Analysis
class_counts = Counter()
for label_path in val_label_paths:
with open(label_path, "r") as f:
lines = f.readlines()
for line in lines:
class_id = line.strip().split()[0]
class_counts[class_id] += 1
df_class_distribution = pd.DataFrame(class_counts.items(), columns=["Class_ID", "Count"])
df_class_distribution.sort_values(by="Count", ascending=False, inplace=True)
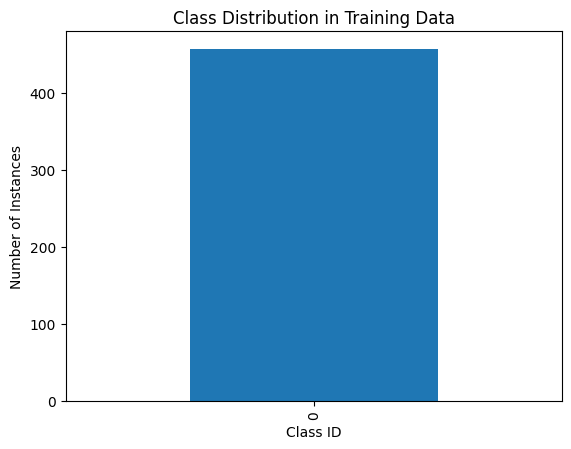
df_class_distribution
| Class_ID | Count | |
|---|---|---|
| 0 | 0 | 457 |
# 📌 Step 10: Plot Class Distribution
df_class_distribution.plot(kind="bar", x="Class_ID", y="Count", legend=False)
plt.title("Class Distribution in Training Data")
plt.xlabel("Class ID")
plt.ylabel("Number of Instances")
plt.show()
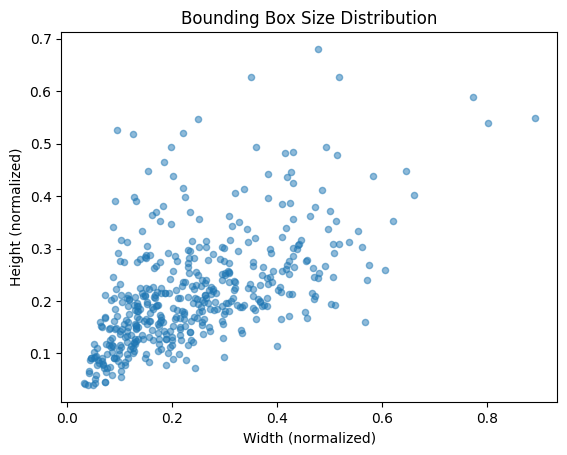
# 📌 Step 11: Bounding Box Size Distribution
bbox_sizes = []
for label_path in val_label_paths:
with open(label_path, "r") as f:
lines = f.readlines()
for line in lines:
_, _, _, width, height = map(float, line.strip().split())
bbox_sizes.append((width, height))
df_bbox = pd.DataFrame(bbox_sizes, columns=["Width", "Height"])
# Scatter plot of bounding box sizes
df_bbox.plot(kind="scatter", x="Width", y="Height", alpha=0.5)
plt.title("Bounding Box Size Distribution")
plt.xlabel("Width (normalized)")
plt.ylabel("Height (normalized)")
plt.show()
# 📌 Step 12: Visualizing Annotations on Images
def plot_sample_image(img_path, label_path):
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
h, w, _ = img.shape
with open(label_path, "r") as f:
lines = f.readlines()
for line in lines:
class_id, x, y, box_w, box_h = map(float, line.strip().split())
x1 = int((x - box_w / 2) * w)
y1 = int((y - box_h / 2) * h)
x2 = int((x + box_w / 2) * w)
y2 = int((y + box_h / 2) * h)
cv2.rectangle(img, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.putText(img, str(class_id), (x1, y1 - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.6, (255, 0, 0), 2)
plt.figure(figsize=(6,6))
plt.imshow(img)
plt.axis("off")
plt.show()
# Test on a few images
for i in range(3):
plot_sample_image(val_label_paths[i], val_label_paths[i])



# 📌 Step 13: Check for Corrupt Images
corrupt_images = []
for img_path in val_label_paths:
try:
img = cv2.imread(img_path)
if img is None:
corrupt_images.append(img_path)
except Exception as e:
corrupt_images.append(img_path)
print(f"❌ Found {len(corrupt_images)} corrupt images.")
# Remove corrupt images
for img_path in corrupt_images:
os.remove(img_path)
print(f"🗑️ Removed: {img_path}")
❌ Found 0 corrupt images.
# 📌 Step 14: Check for Empty Label Files in Training Set
empty_labels = []
train_label_paths = sorted(glob(os.path.join(dataset_extract_path, "labels", "train", "*.txt")))
for label_path in train_label_paths:
if os.stat(label_path).st_size == 0: # If label file is empty
empty_labels.append(label_path)
print(f"❌ Found {len(empty_labels)} empty label files in TRAIN set.")
# Remove empty label files ONLY from the training set
for label_path in empty_labels:
os.remove(label_path)
print(f"🗑️ Removed empty train label file: {label_path}")
❌ Found 77 empty label files in TRAIN set.
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/00019.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/00143.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/01131.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.192648.087.003747.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.192757.391.004579.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.192813.051.004767.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.192813.468.004772.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.192819.718.004847.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193227.870.007826.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193715.346.011277.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193716.262.011288.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193741.502.011591.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193753.914.011740.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193757.162.011779.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193804.326.011865.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193805.243.011876.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193809.075.011922.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193828.381.009679.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193834.981.012233.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193839.544.009813.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193922.130.012799.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193946.454.013091.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.193957.948.013229.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.194043.098.013771.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.194301.360.012956.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.194301.777.012961.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.194307.025.013024.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.194307.359.013028.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.210308.033.006533.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.210310.700.006565.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211125.554.005064.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211155.127.005419.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211428.152.007256.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211428.485.007260.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211428.901.007265.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211430.651.007286.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211432.484.007308.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211432.733.007311.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211522.964.007914.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211535.793.008068.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211827.894.010134.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211852.051.010424.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211954.778.011177.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.211958.610.011223.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.212303.789.013446.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.212328.779.013746.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.212352.687.014033.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.212353.020.014037.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.224041.781.007015.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.224046.363.007070.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161014.224653.973.011483.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.000632.052.008144.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.000635.129.008181.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.000638.377.008220.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.000640.041.008240.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.000817.505.009410.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.000857.989.009896.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001022.789.010914.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001031.944.011024.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001133.941.011768.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001159.249.012072.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001201.165.012095.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001201.507.012099.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001203.413.012122.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001205.333.012145.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001206.329.012157.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001206.413.012158.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001206.497.012159.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001210.077.012202.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001230.726.002511.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001237.237.012528.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001237.649.012533.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001238.401.012542.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161015.001238.901.012548.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161018.182948.628.000786.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161018.183100.933.001654.txt
🗑️ Removed empty train label file: /content/fish_dataset/labels/train/20161018.183356.936.003766.txt
# 📌 Step 17: Check for Duplicate Images Across Splits
train_images = set(glob(os.path.join(dataset_extract_path, "images", "train", "*.jpg")))
val_images = set(glob(os.path.join(dataset_extract_path, "images", "val", "*.jpg")))
test_images = set(glob(os.path.join(dataset_extract_path, "images", "test", "*.jpg")))
duplicates_train_val = train_images.intersection(val_images)
duplicates_train_test = train_images.intersection(test_images)
duplicates_val_test = val_images.intersection(test_images)
print(f"⚠️ {len(duplicates_train_val)} duplicates found between Train and Val.")
print(f"⚠️ {len(duplicates_train_test)} duplicates found between Train and Test.")
print(f"⚠️ {len(duplicates_val_test)} duplicates found between Val and Test.")
⚠️ 0 duplicates found between Train and Val.
⚠️ 0 duplicates found between Train and Test.
⚠️ 0 duplicates found between Val and Test.